2024-09-01 08:31:01
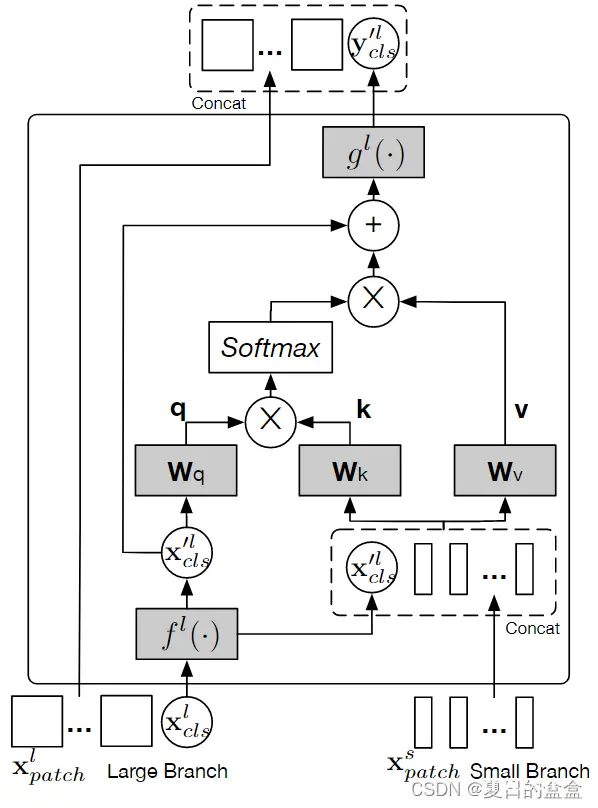
本文提出一个双分支transformer,来组合不同尺寸的图像块(即transformer中的token),以产生更强的图像特征。该方法处理具有不同计算复杂度的两个独立分支的小块和大块token,然后纯粹通过注意力多次...
本文提出一个双分支transformer,来组合不同尺寸的图像块(即transformer中的token),以产生更强的图像特征。该方法处理具有不同计算复杂度的两个独立分支的小块和大块token,然后纯粹通过注意力多次...